Species detection
In this section you will run the species_detection pipeline, which automatically detects and identifies species in the recordings using the BirdNET model, filters results for your target species list, and extracts audio segments containing relevant vocalizations. Additional models will be integrated in future versions of pamflow.
To run the pipeline:
pamflow run --pipeline species_detection
Detection outputs
The pipeline produces two summary figures and two output files.
The figures are stored in data/output/species_detection/:
observations_summary.pdf— a high-level summary showing total observations, number of species detected, and the proportion of recordings with detectionsobservations_per_species.pdf— a bar chart showing the number of detections per species
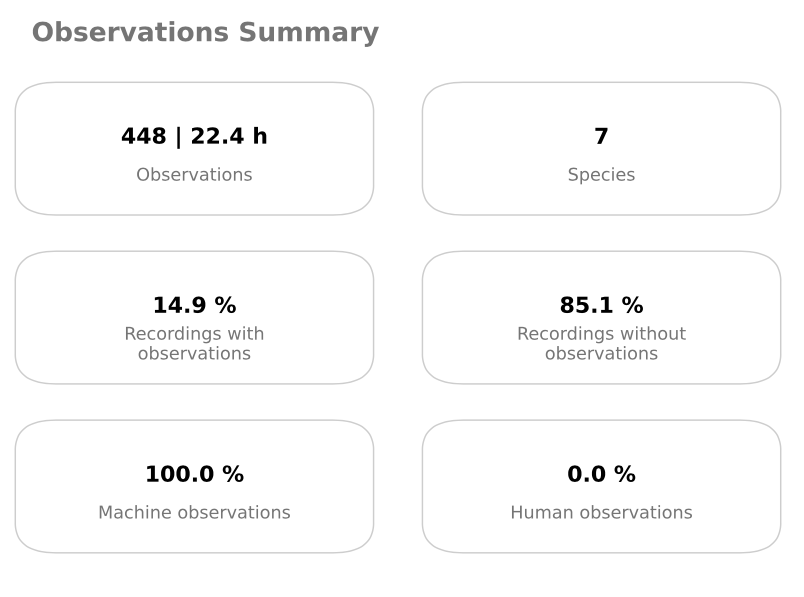
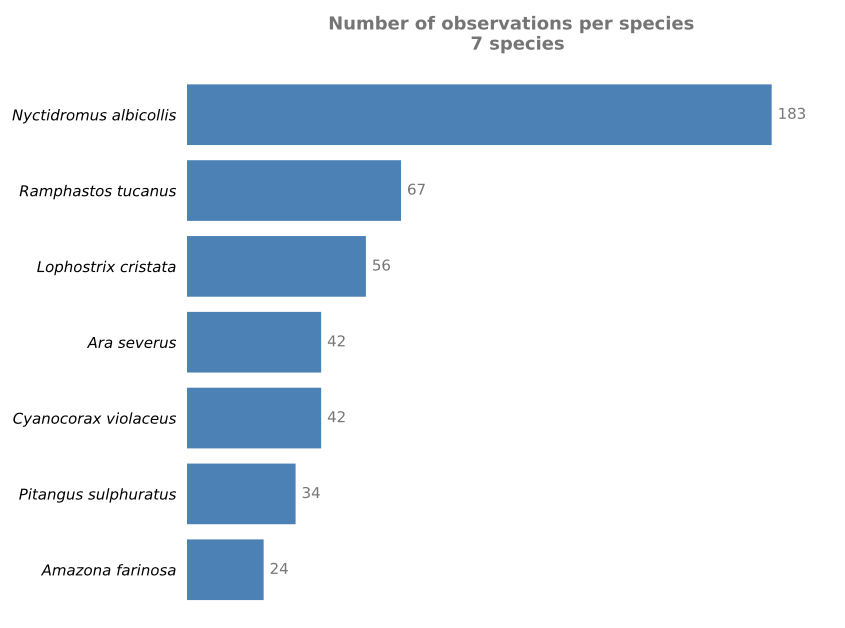
The output files are also stored in data/output/species_detection/:
unfiltered_observations.csv— all detections regardless of speciesobservations.csv— detections filtered to yourtarget_specieslist only (see Input data)
Each row represents one detection, with the audio file name, timestamp, species scientific name, and the model’s confidence score. You can learn more about the file format in the Data Exchange Formats section.
observationID |
deploymentID |
mediaID |
scientificName |
eventStart |
eventEnd |
classifiedBy |
classificationProbability |
… |
|---|---|---|---|---|---|---|---|---|
0 |
MC-002 |
MC-002_20240229_003000.WAV |
Lophostrix cristata |
12.0 |
15.0 |
Birdnet 2.4 |
0.191 |
… |
1 |
MC-002 |
MC-002_20240229_003000.WAV |
Lophostrix cristata |
42.0 |
45.0 |
Birdnet 2.4 |
0.112 |
… |
2 |
MC-002 |
MC-002_20240229_003000.WAV |
Lophostrix cristata |
51.0 |
54.0 |
Birdnet 2.4 |
0.118 |
… |
3 |
MC-002 |
MC-002_20240229_033000.WAV |
Ciccaba virgata |
21.0 |
24.0 |
Birdnet 2.4 |
0.144 |
… |
4 |
MC-002 |
MC-002_20240229_033000.WAV |
Ciccaba virgata |
30.0 |
33.0 |
Birdnet 2.4 |
0.103 |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
Note
Detection confidence scores are low by default — pamflow reports all detections above 0.1, so results should always be reviewed carefully. For example, Lophostrix cristata detections in this dataset are suspicious given that the deployment site is a pasture, where this forest owl would be unexpected. The audio segments and annotation files in the following steps are designed precisely to help with this review. For further guidance on interpreting model outputs, see Wood and Kahl (2024).
Audio segments
To validate the detections, audio segments for each target species are saved in data/output/species_detection/segments/, with one subfolder per species. These clips can be shared with bird experts for manual review and confirmation. The number of segments selected per species can be configured in conf/local/parameters.yml.
Each clip is named following this structure:
<classificationProbability>_<originalFileName>_<startTime>_<endTime>.WAV
This makes it easy to identify the source recording, the time of the vocalization, and the model’s confidence in its identification.
Data annotation
To make expert review straightforward, one Excel file per target species is generated in data/input/manual_annotations/. Each file lists the selected audio segments for that species. Once the audio clips have been reviewed, the expert only needs to fill in two columns:
positive— typetrueif the detection is correct,falseif notdetectedSpecies— if the detection is incorrect, type the actual species name (if known)
The completed annotation files feed back into pamflow in subsequent steps to refine and validate the final results.
For example, the annotation file for Amazona farinosa looks like this:
segmentsFilePath |
filePath |
classificationProbability |
eventStart |
eventEnd |
scientificName |
positive |
detectedSpecies |
|---|---|---|---|---|---|---|---|
0.841_MC-009_20240301_073000_36.0_39.0.WAV |
…/MC-009/MC-009_20240301_073000.WAV |
0.841 |
36 |
39 |
Amazona farinosa |
||
0.684_MC-009_20240301_073000_0.0_3.0.WAV |
…/MC-009/MC-009_20240301_073000.WAV |
0.684 |
0 |
3 |
Amazona farinosa |
||
0.659_MC-009_20240301_073000_33.0_36.0.WAV |
…/MC-009/MC-009_20240301_073000.WAV |
0.659 |
33 |
36 |
Amazona farinosa |
||
0.653_MC-009_20240301_073000_30.0_33.0.WAV |
…/MC-009/MC-009_20240301_073000.WAV |
0.653 |
30 |
33 |
Amazona farinosa |
Wrap-up
Congratulations on completing the tutorial! You have gone through the main pamflow workflow: from organizing and loading field data, to running quality checks on your recorders, detecting target species, and preparing audio segments for expert validation. These steps cover the core of what pamflow is designed to do — turning raw acoustic recordings into structured, reusable, and interpretable data.
You are now ready to run pamflow with your own data. Note that all pipelines can also be run node by node for greater control over each step — see the Pipeline details section for a full reference, including additional pipelines such as graphical_soundscapes and acoustic_indices. If you run into any issues or have suggestions, feel free to open an issue on the GitHub repository. For a deeper understanding of the data formats and outputs, refer to the Data Exchange Formats section.